
Há alguns dias, fizemos uma entrevista de lançamento desta coluna e, apesar de termos conversado por quase uma hora sobre diversos temas relacionados a IA, um tema que chamou a atenção de várias pessoas foi quando, ao final da entrevista, eu comentava rapidamente que temia que poderíamos estar vivendo uma nova bolha tecnológica com a IA.
Um dia depois do lançamento da coluna, vimos uma convulsão das bolsas de tecnologia causadas por algumas empresas chinesas. Em um dia, trilhões de dólares desapareceram do mercado, e uma das principais empresas do setor, a NVidia, perdeu 17% do valor de suas ações, equivalentes a quase 600 Bilhões de Dólares, ou seja, quase o PIB da Argentina.
Antes de discutirmos o que fizeram (e não fizeram) essas empresas chinesas e por que causaram essas perdas, gostaria de começar esta coluna discutindo algo mais fundamental: o que é uma bolha de tecnologia e porque é plausível que estejamos vivendo uma.
Em um belo artigo de novembro do ano passado, o filósofo da informação Luciano Floridi analisa vários exemplos históricos de bolhas de tecnologia (incluindo a bolha.com há mais de duas décadas). Ele propõe um conjunto de características comuns nas quais eu me inspiro: (1) presença de uma tecnologia com grande potencial disruptivo, mas pouco compreendida; (2) grande especulação de investimentos descolada da realidade; (3) euforia da mídia; (4) critérios não convencionais de avaliação e valoração; (5) participação de investidores individuais; (6) fraca regulação. Assim como ele, julgo que o setor de IA atual apresenta todos esses sintomas.
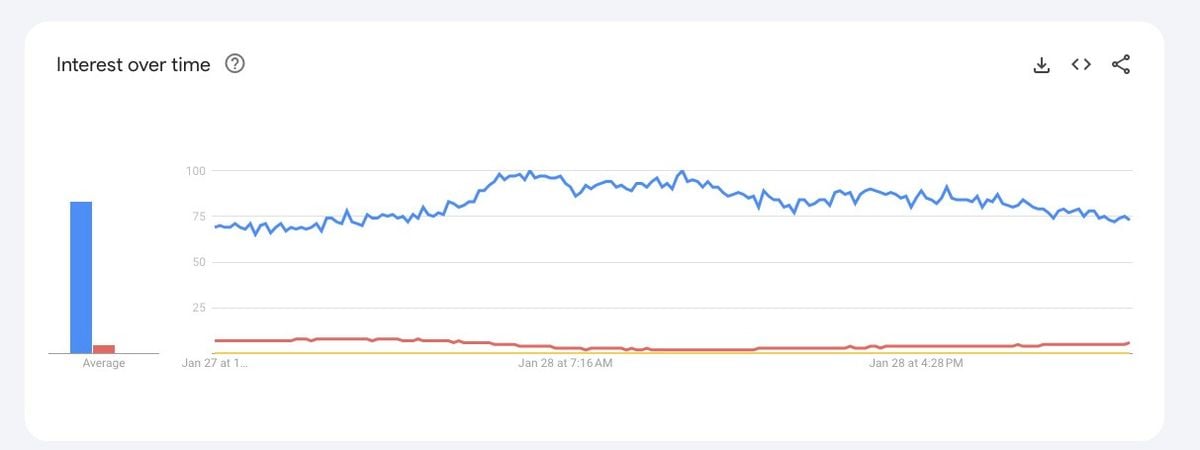
Comecemos pelo papel da mídia (3), incluindo obviamente as redes sociais. Desde o lançamento do ChatGPT pela OpenAI em 2022, o tópico explodiu na consciência coletiva. O gráfico abaixo mostra uma comparação do número de buscas de ChatGPT (em azul) com Taylor Swift - a artista mais popular do mundo (em vermelho), e a guerra Rússia e Ucrania (em amarelo). O gráfico fala por si. Acompanhando a explosão de interesse tivemos também uma explosão de ruído e desinformação gerando apreensão em investidores individuais (5), e possivelmente volatilidade de investimentos. Além disso, o ruído envolve não só o publico geral, mas também empresas que mudam suas estratégias de marketing propagandeando seus serviços e produtos como sendo “inteligentes” ou “usando IA”. Isso retroalimenta a confusão e gera ainda mais instabilidade e possível volatilidade.
Como eu comentava nos últimos dias, IA não é uma coisa só. Recentemente, o setor resolveu apostar todas as suas fichas em um subconjunto muito reduzido da área, as chamadas Redes Neurais Profundas (RNPs) - algoritmos genéricos que não são programados, mas treinados para aprender a detectar padrões estatísticos a partir de montanhas de dados.
Mais do que uma aposta nessas redes, o setor apostou que tudo que seria necessário para produzir uma inteligência comparável ou superior a humana seria escala, ou seja, aumentando continuamente a quantidade de dados e a capacidade de processamento, a “inteligência” desses sistemas aumentaria exponencialmente.
Essa aposta teve até agora consequências muito diretas: a necessidade contínua de aquisição de dados - essas redes precisam de muitos dados para funcionarem (ex: GPT-4 foi treinado com uma enorme fração dos dados disponíveis na internet), alto custo de treinamento (ex: treinar GPT-4 teria custado U$ 100 milhões de dólares), e altíssimo investimentos em processadores extremamente avançados (ex: GPT-4 usou 25.000 processadores avançados da Nvidia para ser treinado).
Só isso já deveria deixar preocupado e se perguntando qualquer investidor atento: essa dependência de tantos dados é sustentável? Uma vez usada toda a web, onde acharíamos mais dados na mesma escala para continuar treinando e supostamente evoluindo esses sistemas? Quais são os produtos matadores (killer applications) desses sistemas que agregariam valor na vida de pessoas e empresas a ponto de torná-los lucrativos na economia real?
Por exemplo, há algumas semanas, a OpenAI teria reportado um prejuízo de US$ 5 bilhões, estaria perdendo dinheiro em um dos seus principais produtos (ChatGPT Pro), e mesmo assim continuaria sendo avaliada em mais de US$ 100 bilhões.
Isso é um exemplo do que citamos em (4): esses produtos não estão sendo avaliados por métricas reais de negócio (ex: retorno de investimento) mas por parâmetros como tamanho da rede usada, investimento em processadores, quantidades de dados usados no treinamento – análogos a indicadores como quantidade de visitas (page views) e de cliques (click throughs) usados na época da bolha .com.
Para piorar a situação, devido à ausência de regulação apropriada (6), essas empresas redefinem os critérios de cumprimento de suas promessas (ex: a redefinição constante do que é atingir inteligência no nível humano), não provêm transparência e auditabilidade sobre o funcionamento dos seus produtos, e não oferecem mecanismos para que suas autoproclamadas conquistas sejam verificadas por entidades independentes.
Agora vamos a um ponto crucial: as limitações intrínsecas da tecnologia (1). RNPs demonstraram um desempenho ímpar em uma das dimensões da inteligência (percepção) e um avanço em alguns pontos específicos de competência linguística (elas dominaram a sintaxe da linguagem humana, mas, na minha opinião, não aspectos semânticos e de compreensão real da linguagem). Dimensões necessárias, mas não suficientes: a inteligência é multifacetada e vai muito além desses dois aspectos incluindo, por exemplo, a capacidade de responder a situações completamente novas, explicar seu processo decisório, e saber o limite das suas próprias capacidades (ex: responder que não sabe responder ao invés de inventar informações).
Muitos de nós cientistas acreditamos que alguns desses requisitos não podem ser satisfeitos sem inovações importantes, ou seja, a combinação de mais dados, mais capacidade de processamento, mas com o mesmo modelo tecnológico não será suficiente para satisfazê-los. A hipótese de que somente escala seria suficiente vem sendo insistentemente testada mais de uma dúzia de vezes nos últimos anos (em um dos experimentos mais caros da história) e, até agora, repetidamente falsificada.
Então, o que fizeram as empresas chinesas nas últimas semanas? Primeiro, a empresa DeepSeek desenvolveu um sistema capaz de competir com os modelos de linguagem conhecidos, com desempenho similar, mas com 1/50 do custo de treinamento. Em seguida, apresentou um sistema chamado r1 (funcionalmente equivalente ao o1 da OpenAI), mas com a vantagem de ser mais transparente. Tudo isso realizado sem a necessidade de milhares de chips de última geração da Nvidia.
Depois disso, a ByteDance (dona do TikTok) apresentou um outro modelo ainda mais barato. A queda significativa nesses custos permitiria a DeepSeek e ByteDance cobrarem uma fração do custo do ChatGPT pelos seus produtos.
Esses resultados lançam uma sombra sobre o modelo de negócios de empresas como OpenAI. Afinal, qual seria seu diferencial competitivo se não custo, menor impacto ambiental, maior transparência, menor necessidade de dados, e maior desempenho? Elas também causaram um enorme impacto no valor da Nvidia, afinal, se existem modelos de linguagem equivalentes e que podem ser treinados com menos processadores e esses menos sofisticados, os produtos topo de linha de empresas como Nvidia teriam uma demanda muito menor do que se esperava.
Por fim, a DeepSeek teria desenvolvido seus produtos a partir da evolução de um modelo da Meta disponibilizado abertamente. Isso demonstra a possibilidade de comoditização desses modelos de linguagem, com consequente perda do diferencial e, portanto, do valor de modelos fechados como o da OpenAI.

O que não fizeram essas empresas? Como ainda baseadas no mesmo modelo tecnológico, elas não resolvem e nem devem resolver quaisquer das limitações referentes a outras dimensões da inteligência e inerentes a tecnologia que cito acima. Além disso, apesar de precisarem de menor quantidade, eles ainda são dependentes de dados (como todo sistema baseado em RNPs). Por fim, apesar de mais transparentes (no que diz respeito ao modelo de linguagem usado), esses sistemas ainda estão longe da transparência adequada. Para isso, seus resultados precisariam ser verificados cuidadosamente por entidades independentes, e os dados usados para treiná-los conhecidos.
Ainda vamos assistir a vários capítulos dessa história, mas reitero a necessidade de atenção aos pontos (1-6) que discuto acima, e reafirmo minhas duas apostas: a primeira de que uma inteligência artificial mais geral vai ter que esperar avanços científicos e tecnológicos além das apostas atuais, e possivelmente combinando várias técnicas de IA. Tecnologias baseadas exclusivamente em RNPs são muito úteis para resolver vários problemas interessantes e complexos, mas as expectativas sobre elas são equivocadas e irreais. A segunda é que é bastante plausível que estejamos assistindo uma nova bolha tecnológica. Como demonstrado por Floridi, as bolhas tecnológicas não são todas iguais, mas quando acontecem, sua deflação não costuma acontecer de maneira branda e sem traumas.
Notou alguma informação incorreta no conteúdo de A Gazeta? Nos ajude a corrigir o mais rápido possível! Clique no botão ao lado e envie sua mensagem.
Envie sua sugestão, comentário ou crítica diretamente aos editores de A Gazeta.
